

By Nathan Van Allen and Jordan Rouden
Organizations that implement the COPC CX Standard consistently report a return on investment of two to five times within the first year (COPC Inc.). That result does not come from designing a good scorecard. It comes from using one consistently. The design work covered in Parts 1 and 2 of this series creates the instrument. Daily operational discipline is what makes it perform.
Contact center operations typically use two types of balanced scorecards: program-level scorecards that track overall operational performance, and agent-level scorecards that focus on individual development and coaching. Both require structured review cadences, but the audience, the frequency of action, and the purpose of each review are different. A program-level scorecard is reviewed by executive and functional leadership. An agent-level scorecard is reviewed by a supervisor and an individual agent.
This is Part 3 of a three-part series. Part 1 covered the benefits of balanced scorecards for contact center performance management. Part 2 examined the design considerations that determine whether a scorecard performs as intended. This part covers how to put both types of scorecards to work in daily operations.
In this article
- Program-Level Scorecards
- 1a. Data Verification
- 1b. Metric and Target Review
- 1c. Understanding Performance and Taking Action
- Agent-Level Scorecards
- 2a. Monthly Coaching Sessions
- 2b. Coaching Observation
- 2c. Annual Performance Reviews
- Applying Scorecards Across Programs and Sites
- Keeping Both Scorecards Current
- Making It Stick
- Frequently Asked Questions
Program-Level Scorecards
Program-level or site-level scorecards serve as a strategic compass for operations leadership. They track the metrics that reflect overall program health: service level, quality, efficiency, customer satisfaction, and cost. COPC recommends a monthly review cycle involving the executive leadership team, functional leaders across quality, operations, and workforce management, and whoever is responsible for data extraction and analysis.
This monthly review should address three things: verifying the data, reviewing the metrics and targets, and understanding performance well enough to take action. When all three happen consistently, the scorecard drives decisions. When any one is skipped, the scorecard becomes a reporting exercise.
1a. Data Verification
Accuracy and reliability are the foundation of a useful scorecard. Before reviewing performance, the team should verify that the data presented is current, complete, and consistent with what functional leaders are seeing in their own systems. While certain data sources may experience natural delays, the scorecard should generally reflect the most recent complete reporting period.
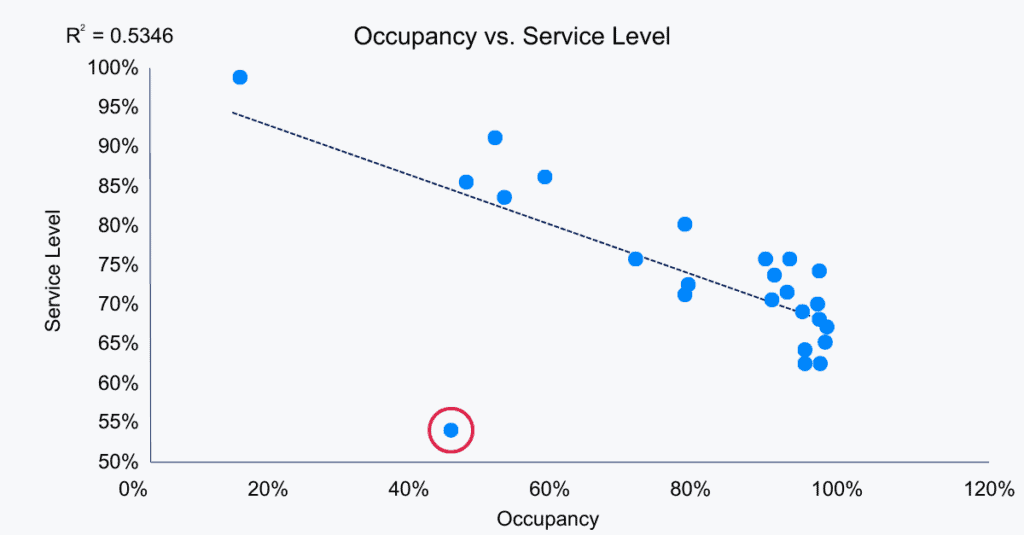
Pay attention to anomalies. Even minor data entry errors can distort category scores and misdirect improvement efforts. If occupancy appears near maximum capacity while agents remain idle, that discrepancy needs investigation before any performance conclusions are drawn. Functional leaders should flag data inconsistencies as soon as they notice them, not wait for the monthly review.
In the example below, the team reviewing the data should investigate the data point circled in red. It does not follow the pattern and was likely supposed to be 94% service level but was entered as 54%.
1b. Metric and Target Review
Each metric on the scorecard should be reviewed against its target, with attention to whether the target itself still serves its purpose. Targets should not change frequently, but they must be addressed when business conditions shift or when a target has lost its meaning.
Two common triggers for target adjustment: a new product or service changes interaction patterns enough to invalidate the current average handle time target, or sustained performance improvement pushes a metric to considerably outperform the target for multiple consecutive months. In the second case, the target has stopped driving behavior and needs to be improved. Thresholds that everyone hits consistently stop distinguishing strong performers from the rest.
1c. Understanding Performance and Taking Action
An accurate scorecard with meaningful targets directs attention to the areas that require immediate action. The review should identify the two or three largest gaps between current performance and target, determine root causes for each gap, and assign ownership for improvement actions with clear timelines.
The critical discipline is separating analysis from the review meeting itself. Root cause analysis should be completed before the meeting by the functional owner of each underperforming metric. The monthly review then focuses on confirming the analysis, making decisions about resource allocation, and holding accountability for actions assigned in the previous cycle. When teams use the review meeting to diagnose problems rather than act on them, the meeting runs long and decisions get deferred.

In Practice
COPC implementations consistently show that the value of a monthly scorecard review compounds over time. In the first two or three cycles, teams use the review to identify and close individual performance gaps. By the sixth month, the accumulated trend data begins surfacing structural patterns: recurring seasonal dips, training cohort effects, and process breakdowns that only become visible across multiple review periods. Operations that sustain the cadence past the initial quarter move from reactive problem-solving to forward-looking resource planning grounded in their own performance history.
Source: COPC Inc., COPC CX Standard

Technology Note
COPC works with organizations running platforms across the full spectrum, from NiCE CXone and Genesys Cloud to custom Power BI and Tableau builds. The platform matters less than the discipline: automate the monthly scorecard package so the team walks into the review with category scores, trend data, and threshold alerts already assembled. Whether that output comes from a native CCaaS reporting suite or a standalone BI layer depends on the operation’s data architecture. The most common failure COPC sees is teams spending the first 30 minutes of a review compiling data that should have been waiting for them when they sat down.
Agent-Level Scorecards
Agent-level scorecards serve a fundamentally different purpose than program-level scorecards. Where the program-level scorecard drives operational decisions, the agent-level scorecard drives coaching, development, and staff engagement. The audience is different (supervisor and agent, not the leadership team), the cadence of action is different, and the conversation is different.
2a. Monthly Coaching Sessions
The agent scorecard should be the primary document in every monthly one-on-one between a supervisor and agent. If the coaching conversation is happening without it, the scorecard is producing data no one is acting on.
COPC guidance on agent scorecard use is specific: focus each coaching session on one or two areas, not the full scorecard. Trying to address every dimension at once produces conversations that cover everything and change nothing. The supervisor and agent should review the evaluation data behind the score, agree on a root cause, and commit to a specific action before the next session.
For agents in a learning curve or actively working toward a target, more frequent check-ins on the agreed focus area accelerate progress without requiring a full scorecard review each time. The monthly session addresses the complete picture; the mid-month check-ins keep momentum on the priority.
As covered in Part 2, COPC’s 2024 Employee Engagement Research draws a direct line between the quality of performance feedback agents receive and how long they stay (COPC Inc., 2024). The scorecard coaching session is where that feedback materializes. When it happens consistently, agents engage with their own performance data over time because the input is tied to something visible and specific, not a manager’s general impression.
2b. Coaching Observation
Coaching is a skill that requires its own development cycle. COPC recommends that organizations regularly observe coaching sessions in the same structured way they evaluate customer interactions. Observation forms that set clear expectations for what a good coaching session looks like give supervisors a framework for improvement, just as quality evaluation forms give agents one.
Recording coaching sessions, where operationally feasible, removes observation bias and allows for more objective review. The goal is to evaluate whether supervisors are selecting the right focus areas, grounding feedback in scorecard data, and driving the conversation toward a specific commitment rather than a general impression.
With that in mind, let’s explore the following key considerations:
- Recognize coaching as a skill that requires ongoing development.
- Incorporate adjustments to hiring and training practices to enhance coaching skills.
- Regularly observe coaching sessions in a way similar to evaluating customer interactions.
- Utilize observation forms as a means to set expectations and evaluate performance.
- Recording sessions can help remove observation bias during reviews.
- Evaluate if supervisors selected the appropriate focus areas for coaching.
2c. Annual Performance Reviews
The agent scorecard proves especially valuable during annual performance reviews. With an aggregated overall score across twelve months, scorecards offer a comprehensive view of an agent’s trajectory rather than a single-point snapshot. Is a newer agent showing steady improvement but not yet at target? Is a tenured high performer trending downward? The scorecard data answers both questions with less subjectivity than a manager’s recollection.
Scorecards also bring objectivity to decisions that are often subjective: stack ranking for incentives, shift bids, skilling assignments, and measuring the success of pilot programs. When these decisions are tied to scorecard data rather than manager impression, they carry more credibility with agents and reduce the perception of favoritism.
Technology Note
Platforms like Calabrio, NICE, and Verint now offer integrated QA-to-coaching workflows that route below-threshold evaluations directly into a supervisor’s coaching queue. AI-native tools like Observe.AI and Cresta go further, surfacing coaching opportunities from 100 percent of interactions rather than a sampled subset. COPC’s guidance is consistent across all of these platforms: the technology should reduce the time supervisors spend identifying who needs coaching and increase the time they spend having the actual conversation. If the platform adds administrative steps between an evaluation result and a coaching note, the workflow needs to be simplified.
Applying Scorecards Across Programs and Sites
In multi-program or multi-site operations, consistent scorecard application is where governance either holds or breaks down. The common failure mode is allowing each program or site to develop its own measurement approach. Within a year, cross-program comparisons become impossible because metrics are defined differently, weighting reflects local decisions, and overall scores are not comparable.
The fix is structural. Standardize the architecture at the organizational level: the same category types, the same weighting methodology, the same calculation rules, the same review cadence. Then build each program within that architecture using program-specific metrics, contractually required thresholds, and agreed-upon targets. Think of it as the difference between a building code and a floor plan. The code governs structure and method consistently across every project. The floor plan reflects the specific needs of each occupant. Every program scorecard follows the same code. No two are necessarily identical.
This approach also transforms client governance in outsourcing environments. Quarterly business reviews move faster when everyone in the room is looking at the same categories, the same weighting, and the same trend data. Cross-program benchmarking becomes actionable: when the top-performing program uses a specific coaching cadence or staffing model, the scorecard data makes the case for transferring that practice.
Technology Note
Enterprise platforms like NiCE CXone, Genesys Cloud, and Sprinklr support multi-site scorecard configurations with program-level threshold variation within a shared weighting structure. Before deploying across programs, COPC recommends confirming three things: the platform can maintain separate targets per program while applying common category weights, the composite view uses weighted (not averaged) category scores, and the data refresh cadence matches the review cycle. Most multi-site scorecard failures COPC encounters are configuration errors, not platform limitations.

Course
Master operational excellence in your contact center and digital services to enhance customer satisfaction, drive sales, and reduce costs with COPC® Best Practices for Customer Experience Operations course.
Keeping Both Scorecards Current
A scorecard that does not evolve with the operation eventually misrepresents performance. The business changes, customer expectations shift, new channels open, and the strategic priorities that drove the original design may no longer reflect what matters. This applies to both program-level and agent-level scorecards.
COPC recommends a structured annual review of every scorecard. Three questions drive it: Are all current metrics still measuring what they were designed to measure? Do the weights still reflect the organization’s actual strategic priorities? Are there dimensions of performance that matter now that were not captured in the original design?
When the scorecard changes, how the change is communicated matters as much as the change itself. Agents and supervisors managing to specific targets need to understand what is changing, why, and how their historical performance is interpreted in light of the revision. A redesign dropped into the organization without explanation erodes the trust that consistent use built.
Technology Note
Most major WEM platforms, including Calabrio, NICE, and Genesys, support scorecard configuration versioning at some level, but few organizations use it rigorously. COPC recommends logging every metric definition change, threshold adjustment, and weight modification with a date and rationale. This audit trail is critical when performance reviews span a scorecard redesign, and essential for maintaining credibility when agents or clients challenge a score based on expectations set under a previous configuration. The organizations that manage this well treat scorecard configuration changes with the same discipline they apply to process documentation changes.
Making It Stick
The organizations that get the most from their balanced scorecards share one characteristic: they treat scorecards as infrastructure, not an initiative. Initiatives end. Infrastructure is maintained, updated, and relied on. A program-level scorecard reviewed consistently for two years changes how leadership thinks about operational performance. An agent-level scorecard used consistently over the same period changes how supervisors coach and how agents engage with their own development. That is what separates operations that improve once from operations that improve continuously.
If you have worked through all three parts of this series, you now have the full framework: why scorecards work, how to design one that holds up in practice, and how to use both program-level and agent-level scorecards as active management systems. The next step is the one that matters most: putting it into practice in your specific operation.

Frequently Asked Questions
How often should a contact center review its balanced scorecard?
Program-level scorecards are reviewed monthly with cross-functional leadership; agent-level scorecards are reviewed in monthly coaching sessions. Metric weights and thresholds are reviewed annually or when there are significant changes (e.g. new products or channels).
What is the difference between a program-level scorecard and an agent-level scorecard?
A program-level scorecard tracks overall operational performance and is reviewed by leadership. An agent-level scorecard tracks individual performance and is used in supervisor-agent coaching sessions.
How should a supervisor structure a scorecard-based coaching session?
Review the full scorecard for context, then narrow to one or two focus areas where you review the evaluation data, agree on a root cause, and commit to a specific action.
How do you apply one scorecard framework across programs with different targets?
Standardize the architecture (category types, weighting methodology, calculation rules) at the organizational level, then build each program within that architecture using program-specific targets. Common code, unique floor plans.
How do you know when a scorecard has become outdated?
Common signals are metrics disconnected from current priorities, thresholds almost all agents hit consistently, and categories that reflect how the operation used to work rather than how it works now. If the review feels like checking boxes rather than making decisions, the scorecard needs updating.
Put your scorecard to work.
→ Contact COPC Inc. to speak with a performance management consultant
→ Read Part 1: Benefits of a Balanced Scorecard for Performance Management
→ Read Part 2: Creating a Balanced Scorecard: What to Consider